Part of this course is exposing you to some of the tools and methodologies that many DHers use. Having at least a little bit of knowledge of these will help you better understand how DH projects or tools are built, what they can do, and what their limitations are. Some of this won’t be easy, and will involve some problem-solving and, once you get your feet wet, a little bit of playing around. But that, too, is part of DH: the experimenting, the play, the figuring out how to do things.
A lot of this you will necessarily have to do on your own, but remember, you’re also part of several communities. Got a question about how something works, or getting an error message? Google it. Chances are you’re not the only one to deal with this problem.
Because we’re building basic skills here, your completion of the following assignments are only being evaluated to the extent that you demonstrate that you have completed them. For each one, please submit a screenshot to the appropriate assignment on Canvas demonstrating that you have completed the assigned tasks(s). Don’t know what a screenshot is, or how to take one on your machine? If so, then figuring those out is your first task.
OK, have at it.
HTML and CSS
Basic coding
Text analysis and topic modeling
Mapping
Social networks
HTML and CSS
HMTL and CSS are essential elements of just about every content management system. In general, HTML constitutes the basic instructions to your computer as to the content of a webpage, and CSS provides the design elements (colors, layout, fonts, and so forth). Complete the free elements of Codecademy’s basic HTML & CSS course. Complete the free (unlocked) lessons through Unit 6. Submit the screenshot of your completion of the Build a Resume segment.
Basic coding
Read the following:
458658
M6R349NX
items
1
chicago-author-date
0
default
asc
108
https://intro-dh-2016.andyschocket.net/wp-content/plugins/zotpress/
%7B%22status%22%3A%22success%22%2C%22updateneeded%22%3Afalse%2C%22instance%22%3A%22zotpress-601acc57d75545defd14b7f0d6c6fcac%22%2C%22meta%22%3A%7B%22request_last%22%3A0%2C%22request_next%22%3A0%2C%22used_cache%22%3Atrue%7D%2C%22data%22%3A%5B%7B%22key%22%3A%22M6R349NX%22%2C%22library%22%3A%7B%22id%22%3A458658%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Marino%22%2C%22parsedDate%22%3A%222006-12-04%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%3Cdiv%20class%3D%5C%22csl-bib-body%5C%22%20style%3D%5C%22line-height%3A%201.35%3B%20padding-left%3A%201em%3B%20text-indent%3A-1em%3B%5C%22%3E%5Cn%20%20%3Cdiv%20class%3D%5C%22csl-entry%5C%22%3EMarino%2C%20Mark%20C.%202006.%20%26%23x201C%3BCritical%20Code%20Studies.%26%23x201D%3B%20%3Ci%3EElectronic%20Book%20Review%3C%5C%2Fi%3E%2C%20no.%20electropoetics%20%28December%29.%20%3Ca%20href%3D%27http%3A%5C%2F%5C%2Fwww.electronicbookreview.com%5C%2Fthread%5C%2Felectropoetics%5C%2Fcodology%27%3Ehttp%3A%5C%2F%5C%2Fwww.electronicbookreview.com%5C%2Fthread%5C%2Felectropoetics%5C%2Fcodology%3C%5C%2Fa%3E.%3C%5C%2Fdiv%3E%5Cn%3C%5C%2Fdiv%3E%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Critical%20Code%20Studies%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Mark%20C.%22%2C%22lastName%22%3A%22Marino%22%7D%5D%2C%22abstractNote%22%3A%22%22%2C%22date%22%3A%2212%5C%2F04%5C%2F2006%22%2C%22language%22%3A%22%22%2C%22DOI%22%3A%22%22%2C%22ISSN%22%3A%22%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Fwww.electronicbookreview.com%5C%2Fthread%5C%2Felectropoetics%5C%2Fcodology%22%2C%22collections%22%3A%5B%222IMK5JW6%22%5D%2C%22dateModified%22%3A%222016-01-09T16%3A26%3A19Z%22%7D%7D%5D%7D
Marino, Mark C. 2006. “Critical Code Studies.”
Electronic Book Review, no. electropoetics (December).
http://www.electronicbookreview.com/thread/electropoetics/codology.
Every computer program is written in a computer language, or “code.” We’re going to learn and use Python. There a zillion languages, many of them used in digital humanities (especially Ruby and Java), but there are good reasons for starting with Python.
As Michelle Moravec has suggested, “invest your time in learning methods not tools.” By this, she doesn’t mean to eschew tools, but rather, to focus on methodology, with the actual tool used being secondary. In other words, even for the exercise we’re doing now, the point is not only to learn python for the sake of knowing python, although I would agree with many that having at least some sense of coding may be completely indispensable, but it’s a pretty good thing to have.
We’re also doing this exercise to learn some methodology for a skill that might come in very handy sometime: how to scrape data from the web. Think of all those digitized files or websites out there, that we can only get data from by downloading the pages. That’s fine for a few dozen or even a few score pages, but what about hundreds? Thousands? That’s where it makes sense to find some way to automate the ingestion of documents, get rid of all that pesky HTML and other formatting necessary for them to get all gussied up for the web anyway, have nice clean files ready for data analysis, and extract some data for analysis. That’s what we’ll be doing with python.
Accordingly, here are the lessons we’ll be doing, from the Programming Historian. First, scroll down to “Introduction to Python.” For actually writing and running your python programs, editors suggest either using the command line or installing Komodo Edit. If either of these work for you, excellent. For the Mac, I much prefer TextWrangler , and Windows folk may like Notepad++ (both of these are free), as Komodo Edit is a lot more complex than our needs warrant for the purposes of this exercise. Another cool option, if you don’t want to install anything, is repl.it, which runs free, online programming environments, including python, that operate on files on your computer (Caveats: you must use the python 2.7 compiler, not the python 3, and I don’t know whether it will invoke the proper libraries; given that python is already on Macs, I would only consider this option for Windows folk).
Another thing to remember: the filename extension, that is, the suffix for python program files is “.py”; no matter what text editor you use, if you’re using one, make sure that you save your files as .py files rather than as .txt files, which tends to be the default on text editors. Of course, you will be working with other files that will need to remain .txt or .html files, but the python programs must have a .py extension.
Then, the lessons to complete:
In canvas, post your final obo.py file and output .html files for two keywords for “Output Keywords” exercise, one for a keyword in the file, the other for a keyword not in the file for an Old Bailey record other than the one used as the example. So, for example, I tried some keywords for the Ordinary’s Account of March 3rd, 1737, and here’s what I got for a hit:
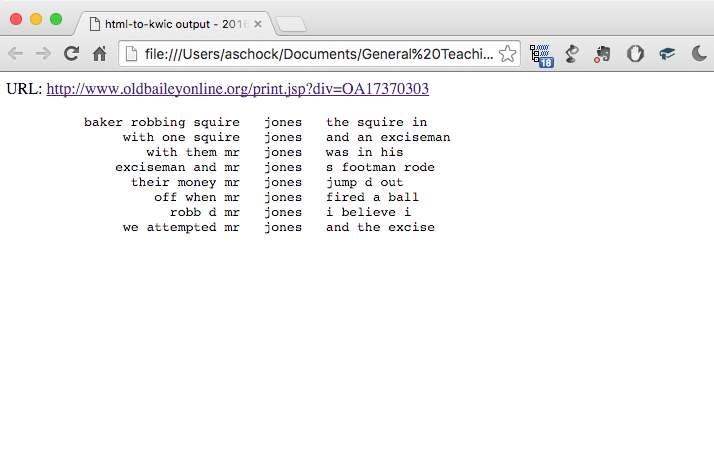
I know, this seems like a lot. But trust me, some of this is review, and most of these lessons go by quickly (several of them under 10 minutes each). I guarantee that we’ll all be able to work through them within a week, with a minimum of pulling of hair and gnashing of teeth.
By the way, last time I did this, people using Windows had trouble with the command line window disappearing. Here’s how to deal with that.
Another interesting read, optional:
458658
7PIIJIWZ
items
1
chicago-author-date
0
default
asc
108
https://intro-dh-2016.andyschocket.net/wp-content/plugins/zotpress/
%7B%22status%22%3A%22success%22%2C%22updateneeded%22%3Afalse%2C%22instance%22%3A%22zotpress-873d5508d899b1575a79c73af4d8e85e%22%2C%22meta%22%3A%7B%22request_last%22%3A0%2C%22request_next%22%3A0%2C%22used_cache%22%3Atrue%7D%2C%22data%22%3A%5B%7B%22key%22%3A%227PIIJIWZ%22%2C%22library%22%3A%7B%22id%22%3A458658%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Ford%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%3Cdiv%20class%3D%5C%22csl-bib-body%5C%22%20style%3D%5C%22line-height%3A%201.35%3B%20padding-left%3A%201em%3B%20text-indent%3A-1em%3B%5C%22%3E%5Cn%20%20%3Cdiv%20class%3D%5C%22csl-entry%5C%22%3EFord%2C%20Paul.%20n.d.%20%26%23x201C%3BWhat%20Is%20Code%3F%20If%20You%20Don%26%23x2019%3Bt%20Know%2C%20You%20Need%20to%20Read%20This.%26%23x201D%3B%20Bloomberg.Com.%20Accessed%20January%209%2C%202016.%20%3Ca%20href%3D%27http%3A%5C%2F%5C%2Fwww.bloomberg.com%5C%2Fgraphics%5C%2F2015-paul-ford-what-is-code%5C%2F%27%3Ehttp%3A%5C%2F%5C%2Fwww.bloomberg.com%5C%2Fgraphics%5C%2F2015-paul-ford-what-is-code%5C%2F%3C%5C%2Fa%3E.%3C%5C%2Fdiv%3E%5Cn%3C%5C%2Fdiv%3E%22%2C%22data%22%3A%7B%22itemType%22%3A%22webpage%22%2C%22title%22%3A%22What%20Is%20Code%3F%20If%20You%20Don%27t%20Know%2C%20You%20Need%20to%20Read%20This%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Paul%22%2C%22lastName%22%3A%22Ford%22%7D%5D%2C%22abstractNote%22%3A%22The%20world%20belongs%20to%20people%20who%20code.%20Those%20who%20don%5Cu2019t%20understand%20will%20be%20left%20behind.%22%2C%22date%22%3A%22%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Fwww.bloomberg.com%5C%2Fgraphics%5C%2F2015-paul-ford-what-is-code%5C%2F%22%2C%22language%22%3A%22%22%2C%22collections%22%3A%5B%5D%2C%22dateModified%22%3A%222016-01-09T18%3A23%3A37Z%22%7D%7D%5D%7D
Ford, Paul. n.d. “What Is Code? If You Don’t Know, You Need to Read This.” Bloomberg.Com. Accessed January 9, 2016.
http://www.bloomberg.com/graphics/2015-paul-ford-what-is-code/.
Text analysis and topic modeling
Some useful intro reading, beyond what we’ve read in Macroanalysis:
458658
M7KRMQTS,NUUBUECV,5QPW24S5,BUPZRQG9
items
1
chicago-author-date
0
default
asc
108
https://intro-dh-2016.andyschocket.net/wp-content/plugins/zotpress/
%7B%22status%22%3A%22success%22%2C%22updateneeded%22%3Afalse%2C%22instance%22%3A%22zotpress-8b1dc5e4a09877948024d7fae9d822a6%22%2C%22meta%22%3A%7B%22request_last%22%3A0%2C%22request_next%22%3A0%2C%22used_cache%22%3Atrue%7D%2C%22data%22%3A%5B%7B%22key%22%3A%22M7KRMQTS%22%2C%22library%22%3A%7B%22id%22%3A458658%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Graham%20et%20al.%22%2C%22parsedDate%22%3A%222012-09-02%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%3Cdiv%20class%3D%5C%22csl-bib-body%5C%22%20style%3D%5C%22line-height%3A%201.35%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%5C%22%3E%5Cn%20%20%3Cdiv%20class%3D%5C%22csl-entry%5C%22%3EGraham%2C%20Shawn%2C%20Scott%20Weingart%2C%20and%20Ian%20Milligan.%202012.%20%26%23x201C%3BGetting%20Started%20with%20Topic%20Modeling%20and%20MALLET.%26%23x201D%3B%20%3Ci%3EProgramming%20Historian%3C%5C%2Fi%3E%2C%20September.%20%3Ca%20href%3D%27http%3A%5C%2F%5C%2Fprogramminghistorian.org%5C%2Flessons%5C%2Ftopic-modeling-and-mallet.html%27%3Ehttp%3A%5C%2F%5C%2Fprogramminghistorian.org%5C%2Flessons%5C%2Ftopic-modeling-and-mallet.html%3C%5C%2Fa%3E.%3C%5C%2Fdiv%3E%5Cn%3C%5C%2Fdiv%3E%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Getting%20Started%20with%20Topic%20Modeling%20and%20MALLET%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Shawn%22%2C%22lastName%22%3A%22Graham%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Scott%22%2C%22lastName%22%3A%22Weingart%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Ian%22%2C%22lastName%22%3A%22Milligan%22%7D%5D%2C%22abstractNote%22%3A%22%22%2C%22date%22%3A%222012-09-02%22%2C%22DOI%22%3A%22%22%2C%22ISSN%22%3A%22%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Fprogramminghistorian.org%5C%2Flessons%5C%2Ftopic-modeling-and-mallet.html%22%2C%22collections%22%3A%5B%2228BCFRQD%22%5D%2C%22dateModified%22%3A%222016-01-09T17%3A33%3A04Z%22%7D%7D%2C%7B%22key%22%3A%22BUPZRQG9%22%2C%22library%22%3A%7B%22id%22%3A458658%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Posner%22%2C%22parsedDate%22%3A%222012-10-29%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%3Cdiv%20class%3D%5C%22csl-bib-body%5C%22%20style%3D%5C%22line-height%3A%201.35%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%5C%22%3E%5Cn%20%20%3Cdiv%20class%3D%5C%22csl-entry%5C%22%3EPosner%2C%20Miriam.%202012.%20%26%23x201C%3BVery%20Basic%20Strategies%20for%20Interpreting%20Results%20from%20the%20Topic%20Modeling%20Tool.%26%23x201D%3B%20Miram%20Posner%3A%20Blog.%20October%2029%2C%202012.%20%3Ca%20href%3D%27http%3A%5C%2F%5C%2Fmiriamposner.com%5C%2Fblog%5C%2F%3Fp%3D1335%27%3Ehttp%3A%5C%2F%5C%2Fmiriamposner.com%5C%2Fblog%5C%2F%3Fp%3D1335%3C%5C%2Fa%3E.%3C%5C%2Fdiv%3E%5Cn%3C%5C%2Fdiv%3E%22%2C%22data%22%3A%7B%22itemType%22%3A%22blogPost%22%2C%22title%22%3A%22Very%20basic%20strategies%20for%20interpreting%20results%20from%20the%20Topic%20Modeling%20Tool%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Miriam%22%2C%22lastName%22%3A%22Posner%22%7D%5D%2C%22abstractNote%22%3A%22%22%2C%22blogTitle%22%3A%22Miram%20Posner%3A%20Blog%22%2C%22date%22%3A%2210%5C%2F29%5C%2F2012%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Fmiriamposner.com%5C%2Fblog%5C%2F%3Fp%3D1335%22%2C%22collections%22%3A%5B%2228BCFRQD%22%5D%2C%22dateModified%22%3A%222016-01-06T15%3A37%3A28Z%22%7D%7D%2C%7B%22key%22%3A%22NUUBUECV%22%2C%22library%22%3A%7B%22id%22%3A458658%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Jockers%22%2C%22parsedDate%22%3A%222011-09-28%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%3Cdiv%20class%3D%5C%22csl-bib-body%5C%22%20style%3D%5C%22line-height%3A%201.35%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%5C%22%3E%5Cn%20%20%3Cdiv%20class%3D%5C%22csl-entry%5C%22%3EJockers%2C%20Matthew%20L.%202011.%20%26%23x201C%3B%26%23xBB%3B%20The%20LDA%20Buffet%20Is%20Now%20Open%3B%20or%2C%20Latent%20Dirichlet%20Allocation%20for%20English%20Majors%20Matthew%20L.%20Jockers.%26%23x201D%3B%20Matthew%20L.%20Jockers.%20September%2028%2C%202011.%20%3Ca%20href%3D%27http%3A%5C%2F%5C%2Fwww.matthewjockers.net%5C%2F2011%5C%2F09%5C%2F29%5C%2Fthe-lda-buffet-is-now-open-or-latent-dirichlet-allocation-for-english-majors%5C%2F%27%3Ehttp%3A%5C%2F%5C%2Fwww.matthewjockers.net%5C%2F2011%5C%2F09%5C%2F29%5C%2Fthe-lda-buffet-is-now-open-or-latent-dirichlet-allocation-for-english-majors%5C%2F%3C%5C%2Fa%3E.%3C%5C%2Fdiv%3E%5Cn%3C%5C%2Fdiv%3E%22%2C%22data%22%3A%7B%22itemType%22%3A%22blogPost%22%2C%22title%22%3A%22%5Cu00bb%20The%20LDA%20Buffet%20is%20Now%20Open%3B%20or%2C%20Latent%20Dirichlet%20Allocation%20for%20English%20Majors%20Matthew%20L.%20Jockers%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Matthew%20L.%22%2C%22lastName%22%3A%22Jockers%22%7D%5D%2C%22abstractNote%22%3A%22%22%2C%22blogTitle%22%3A%22Matthew%20L.%20Jockers%22%2C%22date%22%3A%229%5C%2F28%5C%2F2011%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Fwww.matthewjockers.net%5C%2F2011%5C%2F09%5C%2F29%5C%2Fthe-lda-buffet-is-now-open-or-latent-dirichlet-allocation-for-english-majors%5C%2F%22%2C%22collections%22%3A%5B%2228BCFRQD%22%5D%2C%22dateModified%22%3A%222016-01-06T15%3A37%3A28Z%22%7D%7D%2C%7B%22key%22%3A%225QPW24S5%22%2C%22library%22%3A%7B%22id%22%3A458658%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Graham%20et%20al.%22%2C%22parsedDate%22%3A%222013%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%3Cdiv%20class%3D%5C%22csl-bib-body%5C%22%20style%3D%5C%22line-height%3A%201.35%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%5C%22%3E%5Cn%20%20%3Cdiv%20class%3D%5C%22csl-entry%5C%22%3EGraham%2C%20Shawn%2C%20Ian%20Milligin%2C%20and%20Scott%20Weingart.%202013.%20%26%23x201C%3BTopic%20Modeling%20by%20Hand.%26%23x201D%3B%20In%20%3Ci%3EThe%20Historian%26%23x2019%3Bs%20Macroscope%20%28Working%20Title%29%2C%20Open%20Draft%20Version%3C%5C%2Fi%3E.%20%3Ca%20href%3D%27http%3A%5C%2F%5C%2Fwww.themacroscope.org%5C%2F%3Fpage_id%3D47%27%3Ehttp%3A%5C%2F%5C%2Fwww.themacroscope.org%5C%2F%3Fpage_id%3D47%3C%5C%2Fa%3E.%3C%5C%2Fdiv%3E%5Cn%3C%5C%2Fdiv%3E%22%2C%22data%22%3A%7B%22itemType%22%3A%22bookSection%22%2C%22title%22%3A%22Topic%20Modeling%20by%20Hand%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Shawn%22%2C%22lastName%22%3A%22Graham%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Ian%22%2C%22lastName%22%3A%22Milligin%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Scott%22%2C%22lastName%22%3A%22Weingart%22%7D%5D%2C%22abstractNote%22%3A%22%22%2C%22bookTitle%22%3A%22The%20Historian%27s%20Macroscope%20%28working%20title%29%2C%20open%20draft%20version%22%2C%22date%22%3A%22Autumn%2C%202013%22%2C%22ISBN%22%3A%22%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Fwww.themacroscope.org%5C%2F%3Fpage_id%3D47%22%2C%22collections%22%3A%5B%2228BCFRQD%22%5D%2C%22dateModified%22%3A%222016-01-06T15%3A37%3A28Z%22%7D%7D%5D%7D
Graham, Shawn, Scott Weingart, and Ian Milligan. 2012. “Getting Started with Topic Modeling and MALLET.”
Programming Historian, September.
http://programminghistorian.org/lessons/topic-modeling-and-mallet.html.
Posner, Miriam. 2012. “Very Basic Strategies for Interpreting Results from the Topic Modeling Tool.” Miram Posner: Blog. October 29, 2012.
http://miriamposner.com/blog/?p=1335.
Jockers, Matthew L. 2011. “» The LDA Buffet Is Now Open; or, Latent Dirichlet Allocation for English Majors Matthew L. Jockers.” Matthew L. Jockers. September 28, 2011.
http://www.matthewjockers.net/2011/09/29/the-lda-buffet-is-now-open-or-latent-dirichlet-allocation-for-english-majors/.
Graham, Shawn, Ian Milligin, and Scott Weingart. 2013. “Topic Modeling by Hand.” In
The Historian’s Macroscope (Working Title), Open Draft Version.
http://www.themacroscope.org/?page_id=47.
Then, complete the the Getting Started with Topic Modeling and MALLET tutorial. Submit two screenshots. One, like Figure 8 in the tutorial, should show the output of a train-topics command on the sample data set discussed in the tutorial, but indicates that you generated 15 topics instead of the default 10. The other should, like Figure 10 in the tutorial, show a screenshot of the tutorial_composition.txt file generated by your 15-topic model opened in a spreedsheet (Excel if you have it is fine; I often use LibreOffice, which is free and open source).
Mapping
Some useful intro reading:
458658
X5KKIIDD
items
1
chicago-author-date
0
default
asc
108
https://intro-dh-2016.andyschocket.net/wp-content/plugins/zotpress/
%7B%22status%22%3A%22success%22%2C%22updateneeded%22%3Afalse%2C%22instance%22%3A%22zotpress-10e43fd74332eeb057053022166054ca%22%2C%22meta%22%3A%7B%22request_last%22%3A0%2C%22request_next%22%3A0%2C%22used_cache%22%3Atrue%7D%2C%22data%22%3A%5B%7B%22key%22%3A%22X5KKIIDD%22%2C%22library%22%3A%7B%22id%22%3A458658%7D%2C%22meta%22%3A%7B%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%3Cdiv%20class%3D%5C%22csl-bib-body%5C%22%20style%3D%5C%22line-height%3A%201.35%3B%20padding-left%3A%201em%3B%20text-indent%3A-1em%3B%5C%22%3E%5Cn%20%20%3Cdiv%20class%3D%5C%22csl-entry%5C%22%3E%26%23x201C%3BWhat%20Is%20the%20Spatial%20Turn%3F%20%26%23xB7%3B%20Spatial%20Humanities.%26%23x201D%3B%20n.d.%20Accessed%20January%209%2C%202014.%20%3Ca%20href%3D%27http%3A%5C%2F%5C%2Fspatial.scholarslab.org%5C%2Fspatial-turn%5C%2F%27%3Ehttp%3A%5C%2F%5C%2Fspatial.scholarslab.org%5C%2Fspatial-turn%5C%2F%3C%5C%2Fa%3E.%3C%5C%2Fdiv%3E%5Cn%3C%5C%2Fdiv%3E%22%2C%22data%22%3A%7B%22itemType%22%3A%22webpage%22%2C%22title%22%3A%22What%20is%20the%20Spatial%20Turn%3F%20%5Cu00b7%20Spatial%20Humanities%22%2C%22creators%22%3A%5B%5D%2C%22abstractNote%22%3A%22%22%2C%22date%22%3A%22%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Fspatial.scholarslab.org%5C%2Fspatial-turn%5C%2F%22%2C%22language%22%3A%22%22%2C%22collections%22%3A%5B%227DBUUMSE%22%5D%2C%22dateModified%22%3A%222016-01-06T15%3A38%3A38Z%22%7D%7D%5D%7D
“What Is the Spatial Turn? · Spatial Humanities.” n.d. Accessed January 9, 2014.
http://spatial.scholarslab.org/spatial-turn/.
Complete the following lessons:
Intro to Google Maps and Google Earth. Note: Google Maps Engine Lite has been re-branded Google My Maps. It is slightly different, but includes the same functionality.
Installing QGIS 2.0 and Adding Layers
Creating New Vector Layers in QGIS 2.0
In Canvas, submit no fewer than two distinct screenshots of your maps from the Creating New Vector Layers showing roads and lots.
Social networks
Some useful intro reading:
458658
P98QS6SH,WHIN7NJX,TNHFTERA
items
1
chicago-author-date
0
default
asc
1
108
https://intro-dh-2016.andyschocket.net/wp-content/plugins/zotpress/
%7B%22status%22%3A%22success%22%2C%22updateneeded%22%3Afalse%2C%22instance%22%3A%22zotpress-04cd0636155394d73e119172188e31c9%22%2C%22meta%22%3A%7B%22request_last%22%3A0%2C%22request_next%22%3A0%2C%22used_cache%22%3Atrue%7D%2C%22data%22%3A%5B%7B%22key%22%3A%22TNHFTERA%22%2C%22library%22%3A%7B%22id%22%3A458658%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Healy%22%2C%22parsedDate%22%3A%222013-06-09%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%3Cdiv%20class%3D%5C%22csl-bib-body%5C%22%20style%3D%5C%22line-height%3A%201.35%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%5C%22%3E%5Cn%20%20%3Cdiv%20class%3D%5C%22csl-entry%5C%22%3EHealy%2C%20Kieran.%202013.%20%26%23x201C%3BUsing%20Metadata%20to%20Find%20Paul%20Revere.%26%23x201D%3B%20June%209%2C%202013.%20%3Ca%20href%3D%27http%3A%5C%2F%5C%2Fkieranhealy.org%5C%2Fblog%5C%2Farchives%5C%2F2013%5C%2F06%5C%2F09%5C%2Fusing-metadata-to-find-paul-revere%5C%2F%27%3Ehttp%3A%5C%2F%5C%2Fkieranhealy.org%5C%2Fblog%5C%2Farchives%5C%2F2013%5C%2F06%5C%2F09%5C%2Fusing-metadata-to-find-paul-revere%5C%2F%3C%5C%2Fa%3E.%20%3Ca%20title%3D%27Cite%20in%20RIS%20Format%27%20class%3D%27zp-CiteRIS%27%20href%3D%27https%3A%5C%2F%5C%2Fintro-dh-2016.andyschocket.net%5C%2Fwp-content%5C%2Fplugins%5C%2Fzotpress%5C%2Flib%5C%2Frequest%5C%2Frequest.cite.php%3Fapi_user_id%3D458658%26amp%3Bitem_key%3DTNHFTERA%27%3ECite%3C%5C%2Fa%3E%20%3C%5C%2Fdiv%3E%5Cn%3C%5C%2Fdiv%3E%22%2C%22data%22%3A%7B%22itemType%22%3A%22blogPost%22%2C%22title%22%3A%22Using%20Metadata%20to%20find%20Paul%20Revere%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Kieran%22%2C%22lastName%22%3A%22Healy%22%7D%5D%2C%22abstractNote%22%3A%22%22%2C%22blogTitle%22%3A%22%22%2C%22date%22%3A%226%5C%2F9%5C%2F2013%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Fkieranhealy.org%5C%2Fblog%5C%2Farchives%5C%2F2013%5C%2F06%5C%2F09%5C%2Fusing-metadata-to-find-paul-revere%5C%2F%22%2C%22collections%22%3A%5B%22HSZJ3WZU%22%5D%2C%22dateModified%22%3A%222016-01-06T15%3A44%3A17Z%22%7D%7D%2C%7B%22key%22%3A%22P98QS6SH%22%2C%22library%22%3A%7B%22id%22%3A458658%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Meeks%20and%20Krishnan%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%3Cdiv%20class%3D%5C%22csl-bib-body%5C%22%20style%3D%5C%22line-height%3A%201.35%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%5C%22%3E%5Cn%20%20%3Cdiv%20class%3D%5C%22csl-entry%5C%22%3EMeeks%2C%20Elijah%2C%20and%20Maya%20Krishnan.%20n.d.%20%26%23x201C%3BAn%20Interactive%20Introduction%20to%20Network%20Analysis%20and%20Representation.%26%23x201D%3B%20Accessed%20January%209%2C%202014.%20%3Ca%20href%3D%27http%3A%5C%2F%5C%2Fdhs.stanford.edu%5C%2Fdh%5C%2Fnetworks%5C%2F%27%3Ehttp%3A%5C%2F%5C%2Fdhs.stanford.edu%5C%2Fdh%5C%2Fnetworks%5C%2F%3C%5C%2Fa%3E.%20%3Ca%20title%3D%27Cite%20in%20RIS%20Format%27%20class%3D%27zp-CiteRIS%27%20href%3D%27https%3A%5C%2F%5C%2Fintro-dh-2016.andyschocket.net%5C%2Fwp-content%5C%2Fplugins%5C%2Fzotpress%5C%2Flib%5C%2Frequest%5C%2Frequest.cite.php%3Fapi_user_id%3D458658%26amp%3Bitem_key%3DP98QS6SH%27%3ECite%3C%5C%2Fa%3E%20%3C%5C%2Fdiv%3E%5Cn%3C%5C%2Fdiv%3E%22%2C%22data%22%3A%7B%22itemType%22%3A%22webpage%22%2C%22title%22%3A%22An%20Interactive%20Introduction%20to%20Network%20Analysis%20and%20Representation%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Elijah%22%2C%22lastName%22%3A%22Meeks%22%7D%2C%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Maya%22%2C%22lastName%22%3A%22Krishnan%22%7D%5D%2C%22abstractNote%22%3A%22%22%2C%22date%22%3A%22%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Fdhs.stanford.edu%5C%2Fdh%5C%2Fnetworks%5C%2F%22%2C%22collections%22%3A%5B%22HSZJ3WZU%22%5D%2C%22dateModified%22%3A%222016-01-06T15%3A39%3A48Z%22%7D%7D%2C%7B%22key%22%3A%22WHIN7NJX%22%2C%22library%22%3A%7B%22id%22%3A458658%7D%2C%22meta%22%3A%7B%22creatorSummary%22%3A%22Weingart%22%2C%22parsedDate%22%3A%222011%22%2C%22numChildren%22%3A1%7D%2C%22bib%22%3A%22%3Cdiv%20class%3D%5C%22csl-bib-body%5C%22%20style%3D%5C%22line-height%3A%201.35%3B%20padding-left%3A%202em%3B%20text-indent%3A-2em%3B%5C%22%3E%5Cn%20%20%3Cdiv%20class%3D%5C%22csl-entry%5C%22%3EWeingart%2C%20Scott%20B.%202011.%20%26%23x201C%3BDemystifying%20Networks%2C%20Parts%20I%20%26amp%3B%20II.%26%23x201D%3B%20%3Ci%3EJournal%20of%20Digital%20Humanities%3C%5C%2Fi%3E%201%20%281%29.%20%3Ca%20href%3D%27http%3A%5C%2F%5C%2Fjournalofdigitalhumanities.org%5C%2F1-1%5C%2Fdemystifying-networks-by-scott-weingart%5C%2F%27%3Ehttp%3A%5C%2F%5C%2Fjournalofdigitalhumanities.org%5C%2F1-1%5C%2Fdemystifying-networks-by-scott-weingart%5C%2F%3C%5C%2Fa%3E.%20%3Ca%20title%3D%27Cite%20in%20RIS%20Format%27%20class%3D%27zp-CiteRIS%27%20href%3D%27https%3A%5C%2F%5C%2Fintro-dh-2016.andyschocket.net%5C%2Fwp-content%5C%2Fplugins%5C%2Fzotpress%5C%2Flib%5C%2Frequest%5C%2Frequest.cite.php%3Fapi_user_id%3D458658%26amp%3Bitem_key%3DWHIN7NJX%27%3ECite%3C%5C%2Fa%3E%20%3C%5C%2Fdiv%3E%5Cn%3C%5C%2Fdiv%3E%22%2C%22data%22%3A%7B%22itemType%22%3A%22journalArticle%22%2C%22title%22%3A%22Demystifying%20Networks%2C%20Parts%20I%20%26%20II%22%2C%22creators%22%3A%5B%7B%22creatorType%22%3A%22author%22%2C%22firstName%22%3A%22Scott%20B.%22%2C%22lastName%22%3A%22Weingart%22%7D%5D%2C%22abstractNote%22%3A%22%22%2C%22date%22%3A%22Winter%202011%22%2C%22DOI%22%3A%22%22%2C%22ISSN%22%3A%22%22%2C%22url%22%3A%22http%3A%5C%2F%5C%2Fjournalofdigitalhumanities.org%5C%2F1-1%5C%2Fdemystifying-networks-by-scott-weingart%5C%2F%22%2C%22collections%22%3A%5B%22HSZJ3WZU%22%5D%2C%22dateModified%22%3A%222016-01-06T15%3A39%3A48Z%22%7D%7D%5D%7D
Meeks, Elijah, and Maya Krishnan. n.d. “An Interactive Introduction to Network Analysis and Representation.” Accessed January 9, 2014.
http://dhs.stanford.edu/dh/networks/.
Cite
Weingart, Scott B. 2011. “Demystifying Networks, Parts I & II.”
Journal of Digital Humanities 1 (1).
http://journalofdigitalhumanities.org/1-1/demystifying-networks-by-scott-weingart/.
Cite
Complete Miriam Posner, Getting Started with Palladio
Complete Marten Düring, From Hermeneutics to Data to Networks: Data Extraction and Network Visualization of Historical Sources
On Canvas, upload a screenshot of
- a map you’ve done with Miriam Posner’s Cushner data
- a network you’ve done with Miriam Posner’s Cushner data
- a network that you’ve done with Düring’s Neumann data
- a timeline that you’ve with Düring’s Neumann data
By the way, if you want to visualize your own networks, here’s how with your Facebook or Twitter data.
